Modellierung der extrazellulären Matrix des menschlichen erwachsenen Gehirns nach einer Verletzung zum Ziel der Reparatur
Meriam Ernez - Hector RCD Magdalena Götz
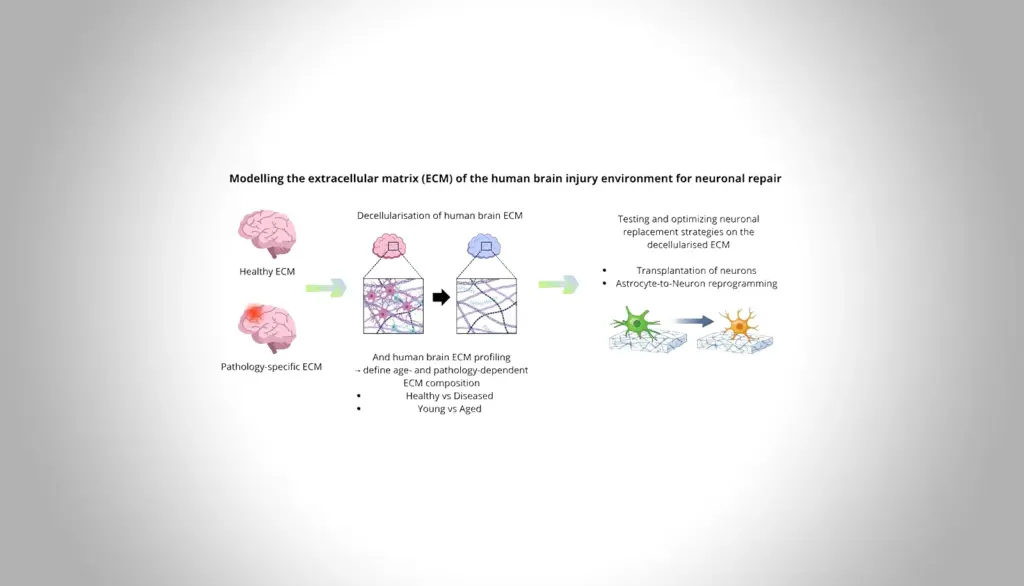
Hirnverletzungen und Neurodegeneration führen zu irreversiblem Neuronenverlust. Dieses Projekt modelliert die Verletzungsumgebung des erwachsenen menschlichen Gehirns durch Dezellularisierung von Hirngewebe adulter Patienten und Charakterisierung der extrazellulären Matrix (ECM). Strategien, abgestorbene Neurone zu ersetzen, einschließlich der Transplantation humaner iPSC-abgeleiteter Neuronen sowie der Reprogrammierung von iPSC-abgeleiteten oder aus Resektionsmaterial isolierten adulten Astrozyten, werden untersucht, um Bedingungen zu definieren, die neuronalen Ersatz über verschiedene Erkrankungen und Altersstufen hinweg ermöglichen.