Modelling extracellular matrix of human adult brain injury for repair
Meriam Ernez - Hector RCD Magdalena Götz
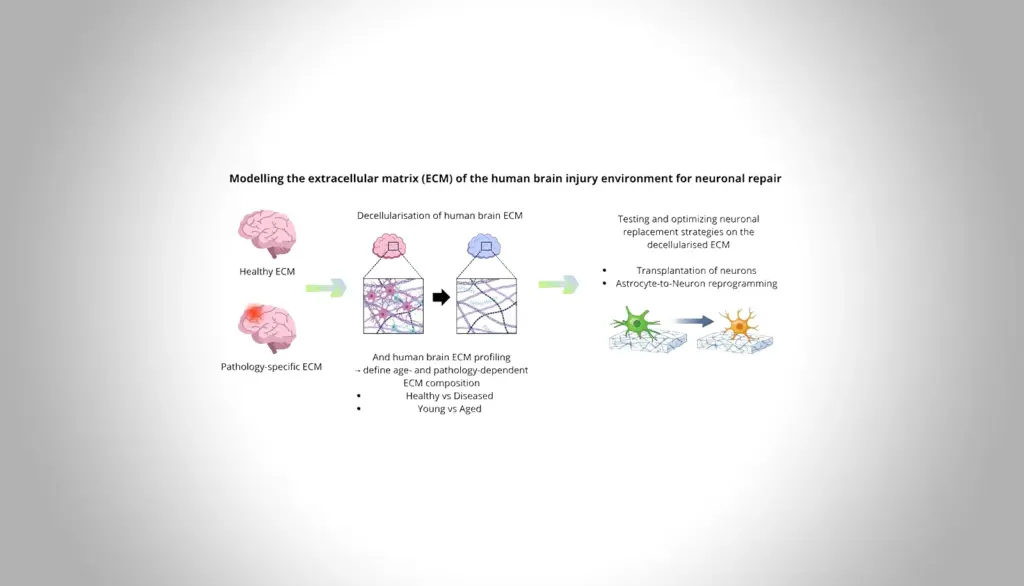
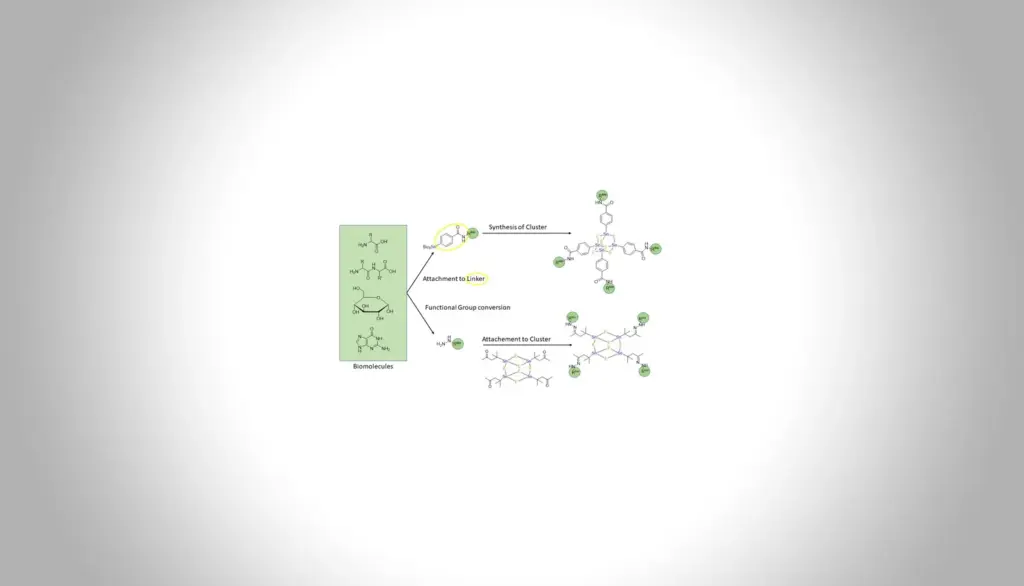
Brain injury and neurodegeneration cause irreversible neuron loss. This project models the adult human brain injury environment by decellularizing adult human brain tissue from patients and characterizing its extracellular matrix (ECM). Neuronal replacement strategies will be tested, including transplantation of human iPSC-derived neurons and reprogramming of iPSC-derived or adult astrocytes isolated from resection material, to define conditions that support neuronal replacement across diseases and ages.